
Whoa…
This does change everything
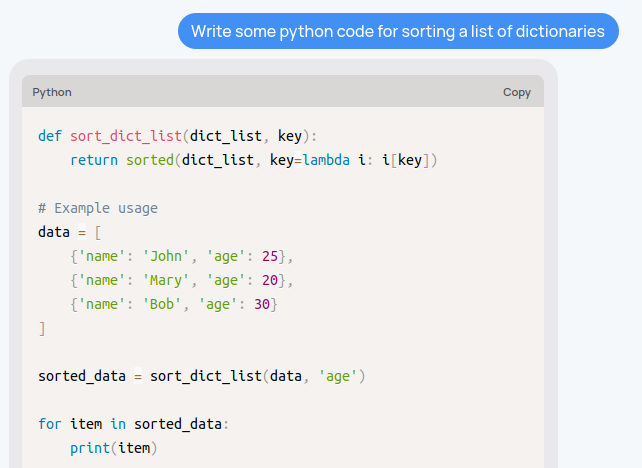
My work life..
Life in the corporate world is very strange to me. My methods are very strange to them.
I don’t know how long I’ll last…

What can I say?
It’s been a long, long time since my last post. I got involved in other things.
But let me assure you, I’m where I need to be.
Georgia Football – Opening Game
First Video on iPhone/Macbook